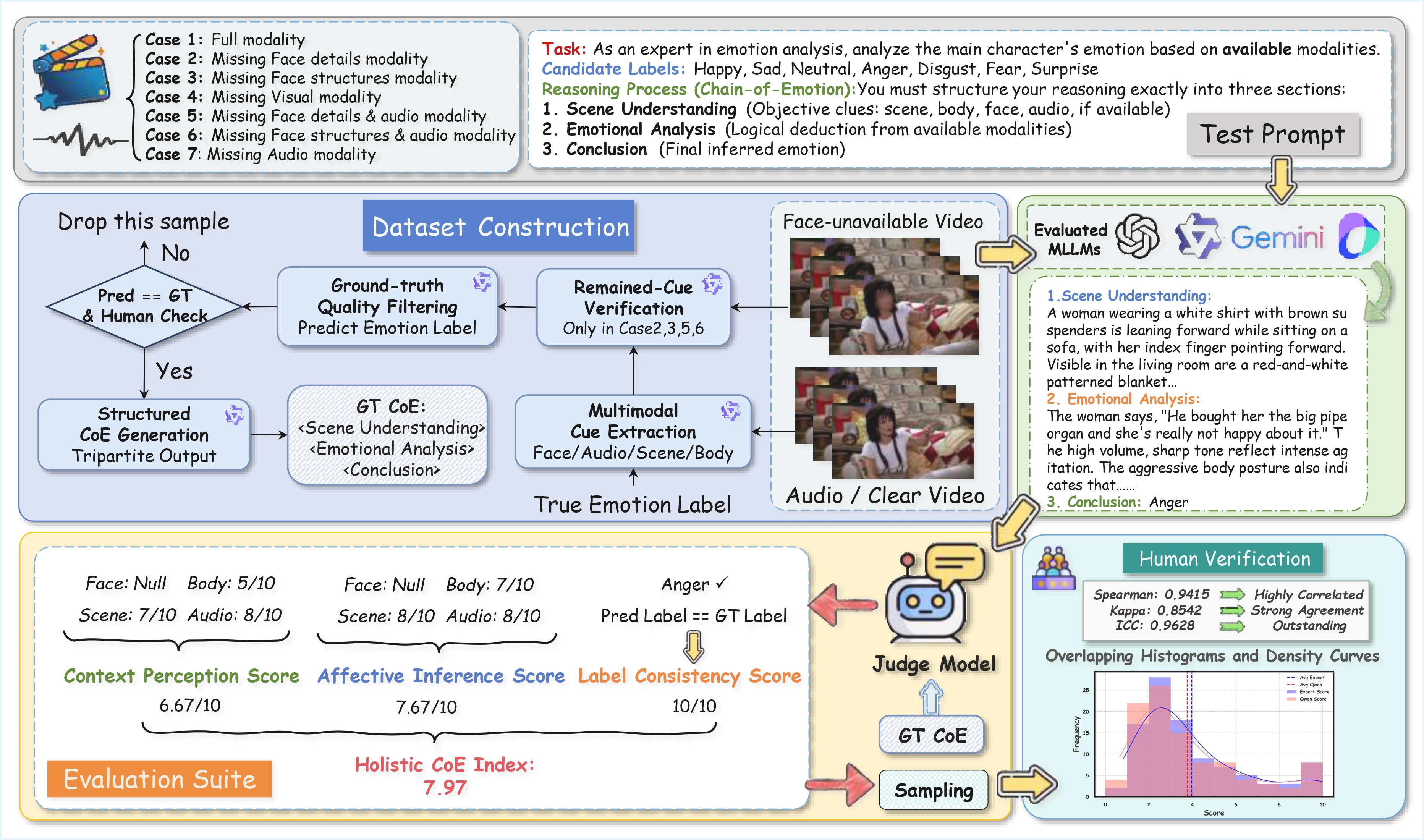
1. Scene Understanding:
The woman with shoulder-length reddish-brown hair in a brown sweater stands in a cozy kitchen. The face is heavily blurred. Wooden shelves with jars fill the background under warm lighting, suggesting domestic comfort as she tilts her head slightly, relaxed and engaged.
2. Emotional Analysis:
Although the face is heavily blurred, we can still infer Happy from the following cues. Other person says "Dis-moi, est-ce que la réponse est pas très proche ?" with a light, playful, inquisitive tone. The warm, domestic scene and her relaxed posture reinforce this cheerful, curious mood.
3. Conclusion:
Happy